
The development of large-scale language models (LLMs) with trillions of parameters is costly and resource-intensive, leading to interest in considering small-scale language models (SLMs) as a more efficient option. Despite its potential, LLMs pose challenges due to significant training costs and operational inefficiencies. Their training mechanisms are difficult to understand and experiments are prohibitively expensive. Additionally, it is often impractical or inefficient to deploy such large-scale models to devices such as PCs and smartphones.
Recent interest in SLMs has led to the emergence of innovative models such as the Phi series, TinyLlama, MobileLLM, and Gemma. Although these models have enriched his SLM field, they do two important things: reproduce the comprehensive capabilities of LLM and establish transparent and scalable training methods that are beneficial to the advancement of both SLM and LLM. I am still struggling in some areas.
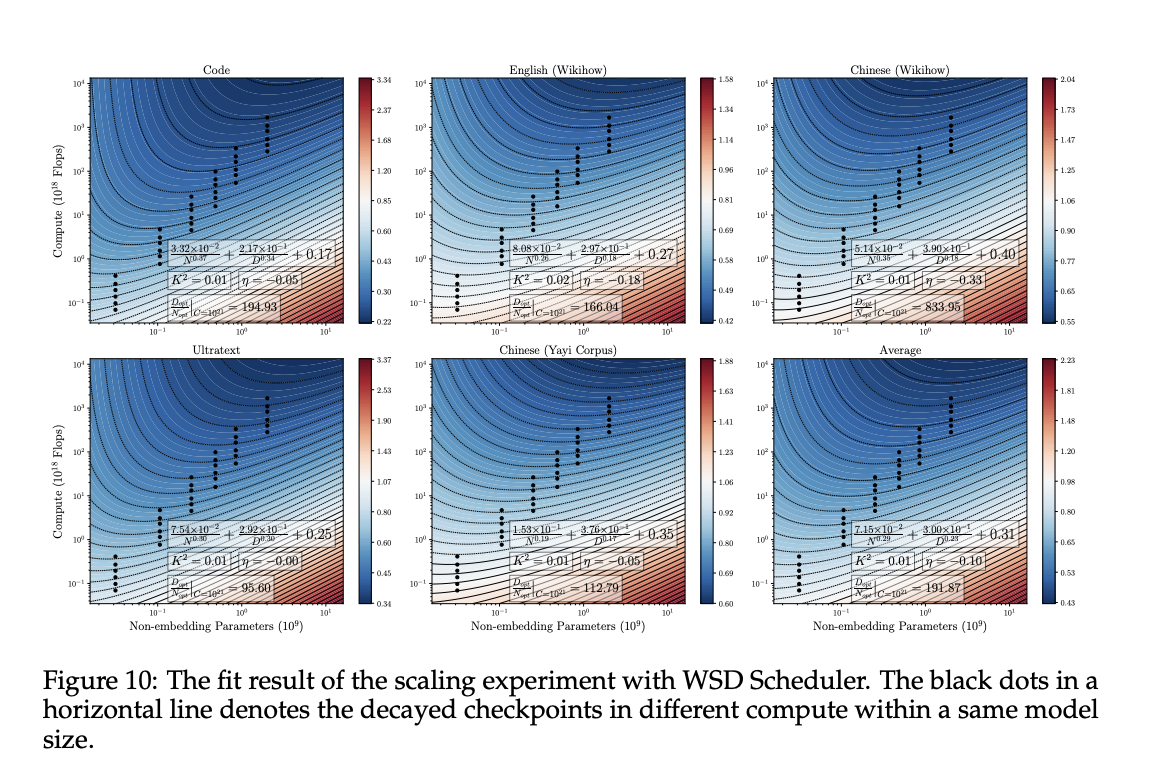
Presented by researchers from Tsinghua University School of Computer Science and Technology and Modelbest Inc. MiniCPM, consists of 1.2B and 2.4B non-embedded parameter variants and is comparable in performance to 7B to 13B LLMs while focusing on SLM. Their approach emphasizes scalability in model and data dimensions for future LLM research. They utilize extensive model wind tunnel experiments for stable scaling and introduce a warm-up-stabilize-decay (WSD) learning rate scheduler for data scaling to facilitate continuous training and domain adaptation. . This method allows efficient study of scaling laws for data models and introduces variants such as MiniCPM-DPO, MiniCPM-MoE, and MiniCPM-128K.
Cosine Learning Rate Scheduler (LRS) is essential for adjusting the learning rate during training. After the warm-up phase, the learning rate gradually decreases according to a cosine curve, and the main parameter T indicates when the decrease first reaches a minimum. Setting T equal to the sum of training steps S is suboptimal. T < S と T > Both S give suboptimal results. Cosine LRS performs best when T = S. This helps find global and local optima with longer high learning rate training and thorough decay phases. Instead of cosine LRS, warm-up-stabilization-decay (WSD) LRS has been proposed, which divides training into warm-up, stabilization, and decay stages to improve performance.
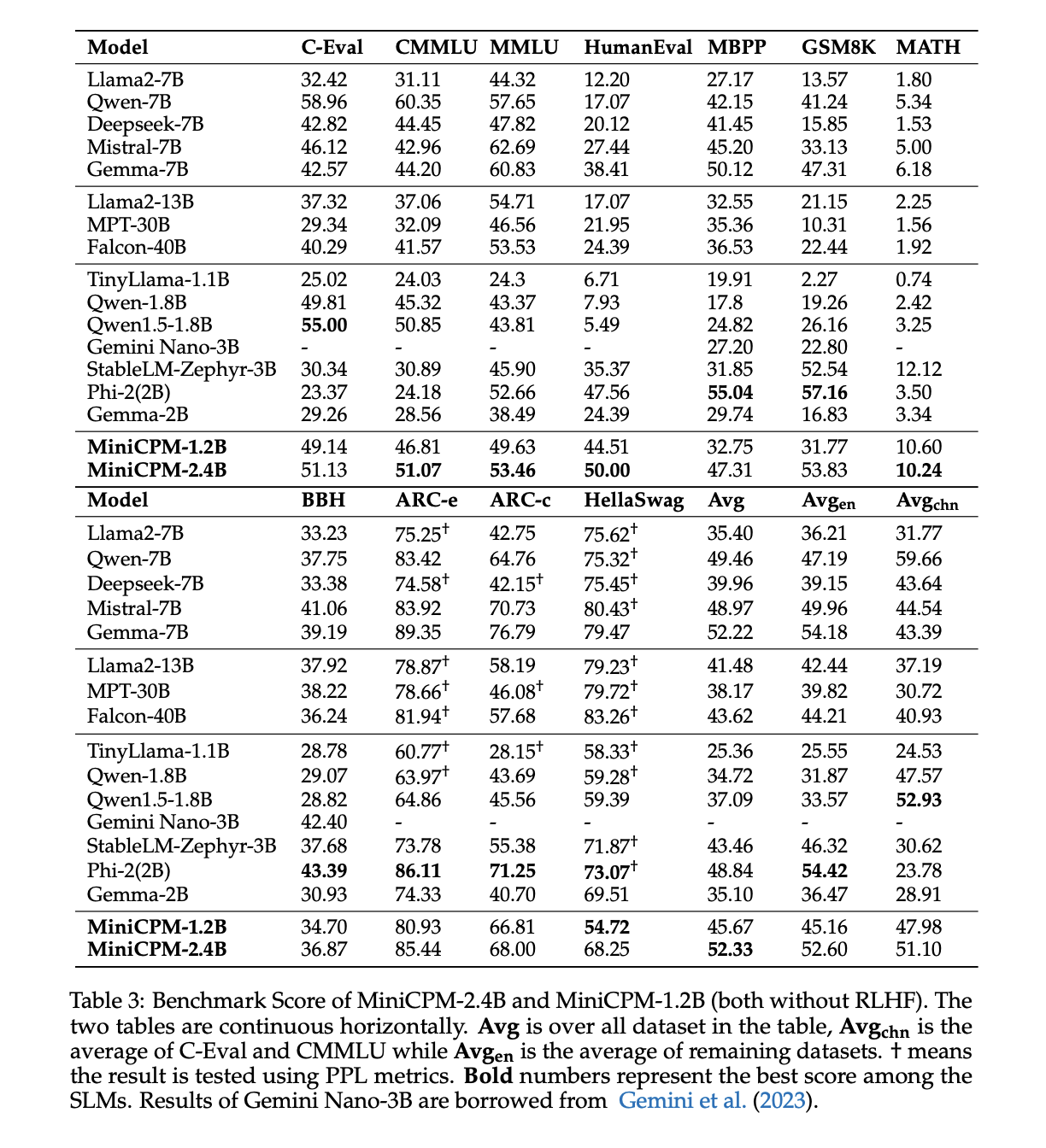
According to our observations, on average, MiniCPM-2.4B ranks highest among SLMs. It performs similar to Mistral-7B-v0.1 in English, but significantly better in Chinese. MiniCPM-2.4B outperforms Llama2-13B in most areas except MMLU, BBH, and HellaSwag, and MiniCPM-1.2B outperforms Llama2-7B except HellaSwag. In general, on knowledge-oriented datasets, BBH is more difficult for SLM than LLM, suggesting that inference ability is more dependent on model size than on knowledge. Phi-2 matches his MiniCPM’s performance on academic datasets, probably due to its focus on educational context in the training data.

In conclusion, this paper presents MiniCPM, which features two SLMs with non-embedded parameters of 2.4B and 1.2B, respectively, and performs better than larger models. Their scalable training methodology shows promise in both model and data size, stimulating potential applications in LLM development. The WSD scheduler enhances continuous training and facilitates research into efficient scaling laws. The MiniCPM family, including DPO, long context and MoE versions, is introduced, and future directions aim to analyze the reduction of losses in the decay stage and enhance the capabilities of his MiniCPM through scaling of model and data sizes. I am.
Please check paper. All credit for this study goes to the researchers of this project.Don’t forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you’ll love Newsletter..
Don’t forget to join us 40,000+ ML subreddits
Want to get in front of an AI audience of 1.5 million people? work with us here


Asjad is an intern consultant at Marktechpost. He is pursuing his B.Tech in Mechanical Engineering from Indian Institute of Technology Kharagpur. Asjad is a machine learning and deep learning enthusiast and is constantly researching the applications of machine learning in healthcare.
 Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more…
Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more… Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish