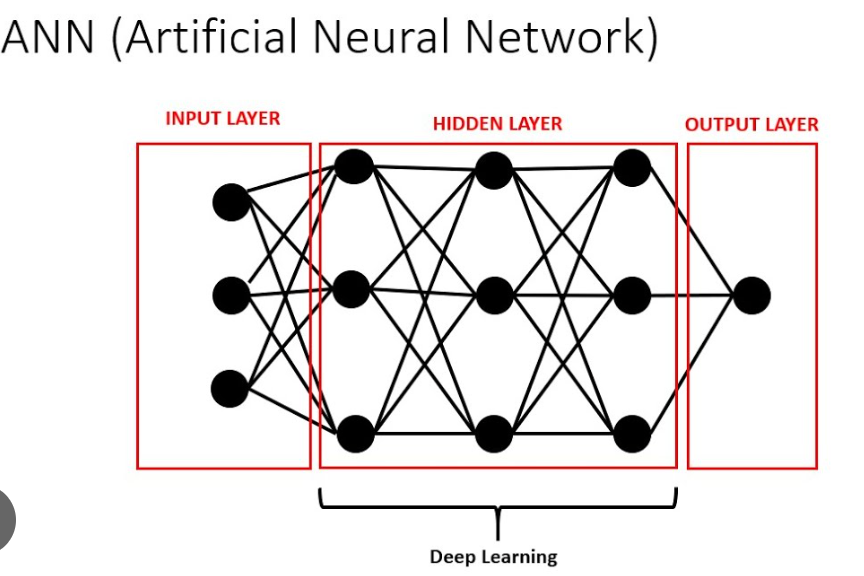
Deep learning is a subset of machine learning, which is itself a subset of artificial intelligence (AI). Deep learning models are inspired by the structure and function of the human brain and are composed of layers of artificial neurons. These models are able to learn complex patterns in data through a process called training, in which the model is iteratively adjusted to minimize errors in predictions.
In this blog post, we will walk through the process of building a simple artificial neural network (ANN) for classifying handwritten digits using the MNIST dataset.
The MNIST dataset (Modified National Institute of Standards and Technology Dataset) is one of the most well-known datasets in the field of machine learning and computer vision. This dataset consists of 70,000 grayscale images of handwritten digits from 0 to 9, each image of size 28 x 28 pixels. The dataset is divided into a training set of 60,000 images and a test set of 10,000 images. Each image is labeled with its corresponding digit.
We’ll use the MNIST dataset provided by the Keras library, which makes it easy to download and use in our model.
Before you can start building a model, you need to import the necessary libraries, which include libraries for data manipulation, visualization, and building deep learning models.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
numpyandpandasUsed for manipulating numbers and data.matplotlibandseabornUsed for data visualization.tensorflowandkerasIt is used to build and train deep learning models.
The MNIST dataset is directly available in the Keras library, so it’s easy to load and use.
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
This line of code downloads the MNIST dataset and splits it into a training set and a test set.
X_trainandy_trainTraining images and their corresponding labels.X_testandy_testTest images and their corresponding labels.
Let’s look at the shape of the training and testing datasets to understand their structure.
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
X_train.shapeoutput(60000, 28, 28)This means that there are 60,000 training images of size 28 x 28 pixels.X_test.shapeoutput(10000, 28, 28)This means that there are 10,000 test images of size 28 x 28 pixels.y_train.shapeoutput(60000,)It shows that there are 60,000 training labels.- `y_test
.shapeoutputs(10000,)` indicates that there are 10,000 test labels.
To understand better, let’s visualize one of the training images and its corresponding labels.
plt.imshow(X_train[2], cmap='gray')
plt.show()
print(y_train[2])
plt.imshow(X_train[2], cmap='gray')The third image from the training set is shown in grayscale.plt.show()Render the image.print(y_train[2])Print the label of the third image (the number that the image represents).
The pixel values of an image range from 0 to 255. To improve the performance of the neural network, we rescale these values to the range of 0 to 255. [0, 1].
X_train = X_train / 255
X_test = X_test / 255
This normalization ensures that the input values fall within a similar range, allowing the neural network to learn more efficiently.
Our neural network expects the inputs to be flat vectors rather than 2D images, so we reshape our training and testing datasets accordingly.
X_train = X_train.reshape(len(X_train), 28 * 28)
X_test = X_test.reshape(len(X_test), 28 * 28)
X_train.reshape(len(X_train), 28 * 28)We reshape the training set from (60000, 28, 28) to (60000, 784) and flatten each 28×28 image into a 784-dimensional vector.- Similarly,
X_test.reshape(len(X_test), 28 * 28)Reshape the test set from (10000, 28, 28) to (10000, 784).
We build a simple neural network with one input layer and one output layer: the input layer has 784 neurons (one per pixel) and the output layer has 10 neurons (one per digit).
ANN1 = keras.Sequential([
keras.layers.Dense(10, input_shape=(784,), activation='sigmoid')
])
keras.Sequential()Create a sequential model with linearly stacked layers.keras.layers.Dense(10, input_shape=(784,), activation='sigmoid')We add a dense (fully connected) layer with 10 neurons, an input shape of 784, and a sigmoid activation function.
Next, compile the model by specifying the optimizer, loss function, and metric.
ANN1.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
optimizer='adam'Specify the Adam optimizer, an adaptive learning rate optimization algorithm.loss='sparse_categorical_crossentropy'Specify a loss function suitable for multiclass classification problems.metrics=['accuracy']Specifies that accuracy should be tracked during training.
Next, train the model on the training data.
ANN1.fit(X_train, y_train, epochs=5)
ANN1.fit(X_train, y_train, epochs=5)We train the model for 5 epochs, where an epoch is one complete pass through the training data.
After training the model, we evaluate its performance on the test data.
ANN1.evaluate(X_test, y_test)
ANN1.evaluate(X_test, y_test)It evaluates the model on the test data and returns the loss and metrics values specified at compile time.
You can use the trained model to make predictions on the test data.
y_predicted = ANN1.predict(X_test)
ANN1.predict(X_test)Generate predictions for the test images.
To see the predicted label for the first test image:
print(np.argmax(y_predicted[10]))
print(y_test[10])
np.argmax(y_predicted[10])Returns the index of the highest value in the prediction vector that corresponds to the predicted digit.print(y_test[10])Print the actual label from the first test image for comparison.
To improve the model, we add a hidden layer with 150 neurons and use the ReLU activation function, which often improves performance in deep learning models.
ANN2 = keras.Sequential([
keras.layers.Dense(150, input_shape=(784,), activation='relu'),
keras.layers.Dense(10, activation='sigmoid')
])
keras.layers.Dense(150, input_shape=(784,), activation='relu')We add a dense hidden layer with 150 neurons and a ReLU activation function.
Compile and train the improved model in the same way.
ANN2.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
ANN2.fit(X_train, y_train, epochs=5)
Evaluate the performance of the improved model on the test data.
ANN2.evaluate(X_test, y_test)
To get a better understanding of the performance of your model, you can create a confusion matrix.
y_predicted2 = ANN2.predict(X_test)
y_predicted_labels2 = [np.argmax(i) for i in y_predicted2]
y_predicted2 = ANN2.predict(X_test)Generate predictions for the test images.y_predicted_labels2 = [np.argmax(i) for i in y_predicted2]Convert the prediction vector into a label index.
Next, we create a confusion matrix and visualize it.
cm = tf.math.confusion_matrix(labels=y_test, predictions=y_predicted_labels2)
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d')
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
tf.math.confusion_matrix(labels=y_test, predictions=y_predicted_labels2)Generate a confusion matrix.sns.heatmap(cm, annot=True, fmt='d')Visualize the confusion matrix with annotations.
In this blog post, we covered the basics of deep learning and walked through the steps to build, train, and evaluate a simple ANN model using the MNIST dataset. We also improved the model by adding hidden layers and using a different activation function. Deep learning models may seem complex at first glance, but they can be built and understood incrementally, allowing you to tackle a wide variety of machine learning problems.
 Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish