
Reinforcement learning (RL) is fundamental to enabling machines to tackle tasks ranging from strategic gameplay to autonomous driving. In this broad field, the challenge of developing algorithms that effectively and efficiently learn from limited interactions with the environment remains paramount. A persistent challenge in RL is achieving high levels of sample efficiency, especially when data are limited. Sample efficiency refers to an algorithm’s ability to learn effective behavior from minimal interaction with the environment. This is critical in real-world applications where data collection is time-consuming, costly, or potentially dangerous.
Current RL algorithms have advanced in increasing sample efficiency through innovative approaches such as model-based learning, where agents build internal models of the environment to predict future outcomes. Despite these advances, achieving consistently good performance across different tasks and domains remains difficult.

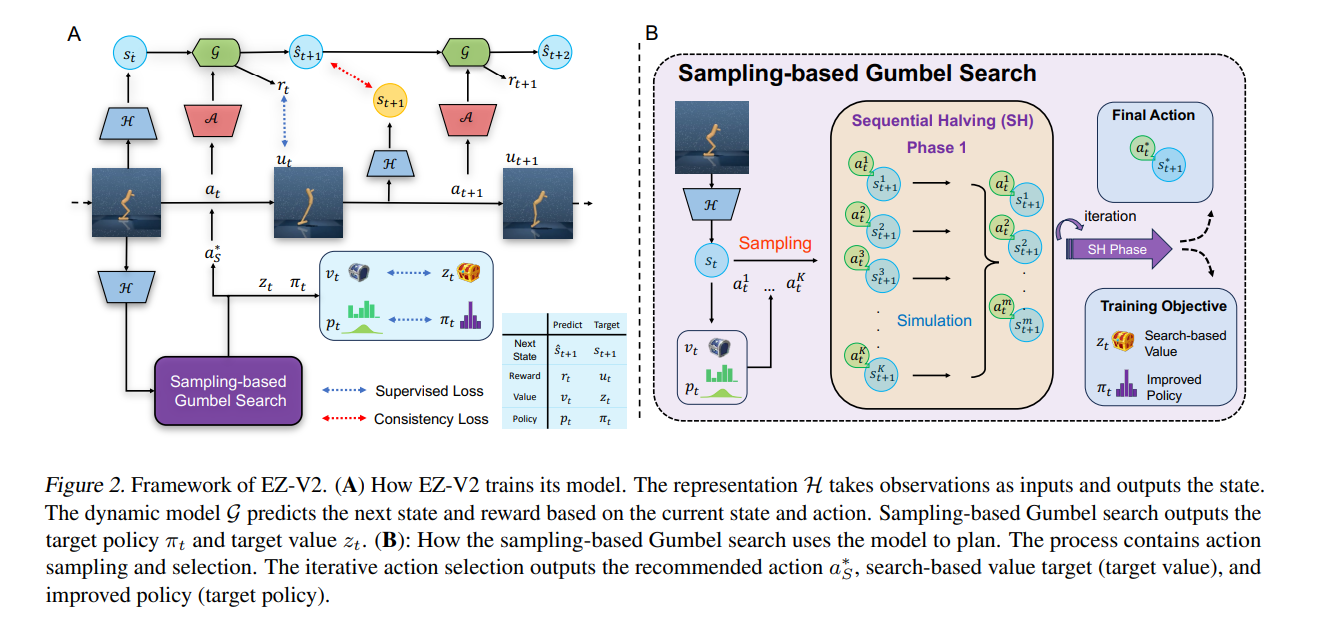
Researchers from Tsinghua University, Shanghai Qizhi Institute, Shanghai and Shanghai Institute of Artificial Intelligence have developed EfficientZero V2 (EZ -V2) has been introduced. This is a feat that has never been achieved before. algorithm. Its design incorporates Monte Carlo Tree Search (MCTS) and model-based planning, and it performs well even in environments with visual, low-dimensional inputs. This approach allows the framework to master tasks that require subtle control and decision-making based on visual cues, which are common in real-world applications.
EZ-V2 employs a combination of representation functions, dynamic functions, policy functions, and value functions, all represented by advanced neural networks. These components facilitate the learning of predictive models of the environment, enabling efficient action planning and policy improvement. Particularly noteworthy is the use of Gumbel search for tree search-based planning, tailored for discrete and continuous action spaces. This approach allows you to efficiently balance exploration and exploitation while ensuring policy improvements. Additionally, EZ-V2 introduces a new search-based value estimation (SVE) technique that leverages imaginary trajectories for more accurate value prediction, especially when handling out-of-policy data. This comprehensive approach allows EZ-V2 to achieve superior performance benchmarks and significantly improves the sample efficiency of RL algorithms.
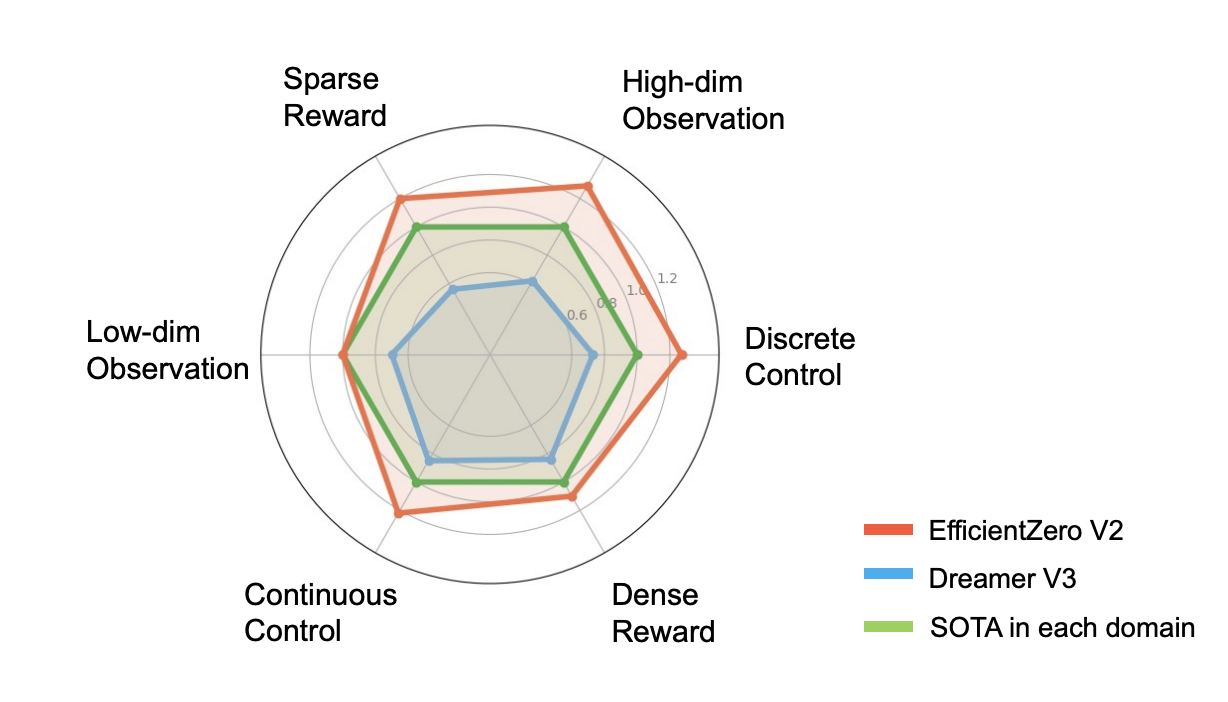
This research paper details the impressive results from a performance perspective. EZ-V2 is more advanced than the popular algorithm DreamerV3, achieving superior results in 50 out of 66 evaluation tasks across a variety of benchmarks, including the Atari 100k. This is an important milestone in RL’s ability to handle complex tasks with limited data. Specifically, on the features grouped under the Proprio Control and Vision Control benchmarks, the framework demonstrated its adaptability and efficiency, outperforming previous state-of-the-art algorithms.

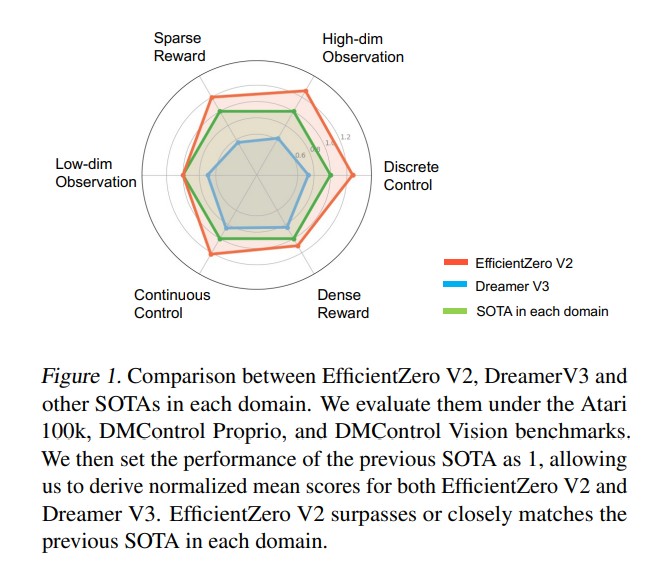
In conclusion, EZ-V2 represents a significant advance in the quest for more sample-efficient RL algorithms. By deftly overcoming the challenges of low rewards and the complexities of continuous control, they have opened new avenues for applying RL in real-world settings. The implications of this research are profound, offering potential breakthroughs in a variety of fields where data efficiency and algorithmic flexibility are paramount.
Please check paper. All credit for this study goes to the researchers of this project.Don’t forget to follow us twitter and google news.participate 38,000+ ML subreddits, 41,000+ Facebook communities, Discord channeland linkedin groupsHmm.
If you like what we do, you’ll love Newsletter..
Don’t forget to join us telegram channel
You may also like Free AI courses….


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated double degree in materials from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast and is constantly researching applications in areas such as biomaterials and biomedicine. With a strong background in materials science, he explores new advances and creates opportunities to contribute.
 [FREE AI WEBINAR] “Build with Google’s new open Gemma model” (March 11, 2024) [Promoted]
[FREE AI WEBINAR] “Build with Google’s new open Gemma model” (March 11, 2024) [Promoted]  Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish