
Latent diffusion models are generative models used in machine learning, especially probabilistic modeling. These models aim to capture the underlying structure and latent variables of a dataset, and often focus on generating realistic samples and making predictions. These represent the evolution of the system over time. It refers to transforming a set of random variables from an initial distribution to a desired distribution through a series of steps or a diffusion process.
These models are based on the ODE solver approach. Although the number of inference steps required is reduced, it still requires significant computational overhead, especially when incorporating classifier-free guidance. Distillation methods such as Guided-Distill are promising but need to be improved due to their intensive computational requirements.
To address such issues, the need for latent consistency models has emerged. Their approach includes a despreading process and treats it as an extended stochastic flock ODE problem. They innovatively predict solutions in latent space, avoiding the need for iterative solutions with numerical ODE solvers. In just 1 to 4 inference steps, you can create incredible compositions of high-resolution images.
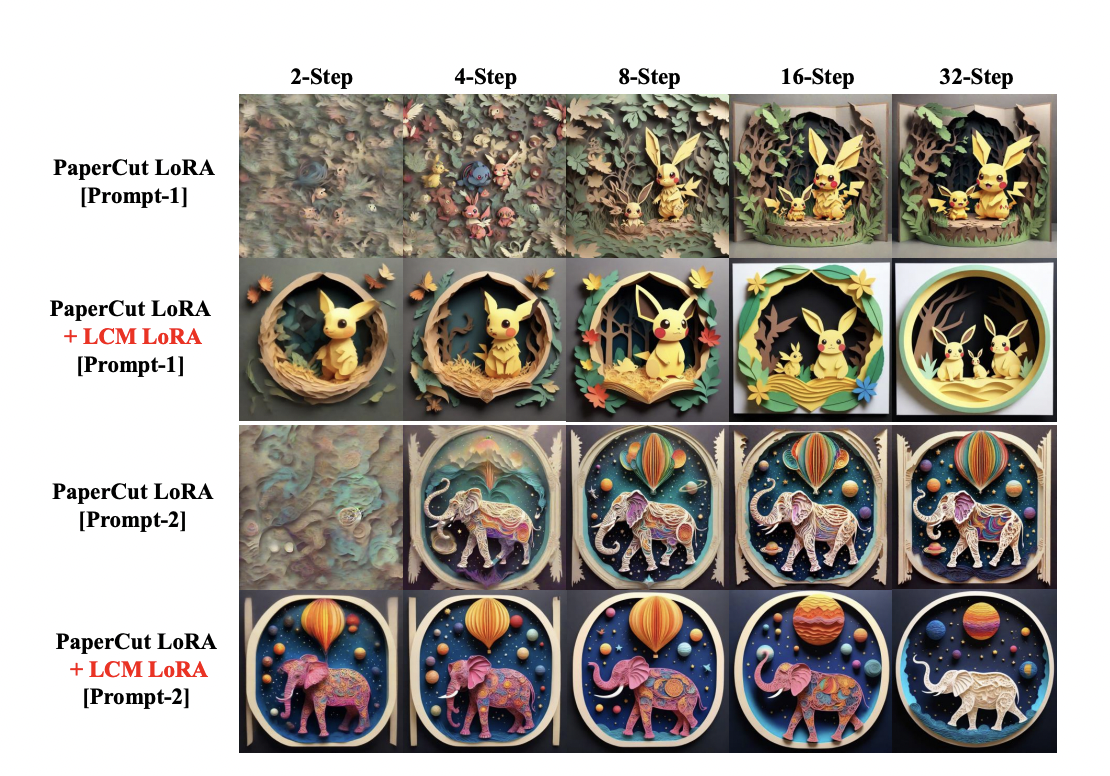
Tsinghua University researchers are expanding the possibilities of LCM by applying LoRA distillation to stable diffusion models such as SD-V1.5, SSD-1B, and SDXL. By achieving superior image generation quality, they extended the scope of LCM to larger models with significantly reduced memory consumption. For specialized datasets such as anime, photorealistic, or fantasy images, you can use latent consistency distillation (LCD) to distill a pre-trained LDM to LCM, or LCF to directly distill LCM. Additional steps are required, such as fine-tuning. But can custom datasets deliver fast inference without training?
To answer this, the team introduced LCM-LoRA as a general-purpose, no-training acceleration module that can be directly connected to a variety of stable diffusion fine-tuning models. Within the LoRA framework, the resulting LoRA parameters can be seamlessly integrated with the original model parameters. The team demonstrated the feasibility of employing his LoRA in a latent consistency model (LCM) distillation process. LCM-LoRA parameters can be directly combined with other LoRA parameters to fine-tune a particular style of dataset. This allows you to generate images of a certain style with minimal sampling steps without the need for further training. Therefore, they represent universally applicable accelerators for various image generation tasks.
This innovative approach significantly reduces the need for iterative steps and enables the rapid generation of high-fidelity images from text input, setting a new standard for state-of-the-art performance. LoRA significantly reduces the amount of parameters to change, resulting in increased computational efficiency and the ability to refine models with significantly less data.
Please check paper and github. All credit for this study goes to the researchers of this project.Also, don’t forget to join us 33,000+ ML SubReddits, 41,000+ Facebook communities, Discord channel, and email newsletterWe share the latest AI research news, cool AI projects, and more.
If you like what we do, you’ll love our newsletter.


Arshad is an intern at MarktechPost. He is currently continuing his international studies. He holds a master’s degree in physics from the Indian Institute of Technology, Kharagpur. Understanding things from the fundamentals leads to new discoveries and advances in technology. He is passionate about leveraging tools such as mathematical models, ML models, and AI to fundamentally understand the essence.
 Join our AI Startups Newsletter to learn about the latest AI startups
Join our AI Startups Newsletter to learn about the latest AI startups  Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish