
Meta is released Llama 3, the latest entry in the Llama series of open generative AI models. More precisely, in the new Llama 3 family the company will debut two models, and the rest will be released at an unspecified future date.
Mehta said the new model Llama 3 8B contains 8 billion parameters, Llama 3 70B contains 70 billion parameters, and the previous generation Llama models Llama 2 8B and Llama 2 70B. He described it as a “huge improvement” compared to the previous. In terms of performance. (Parameters essentially define an AI model’s skill at a problem, such as analyzing or generating text. Models with more parameters are generally more capable than models with fewer parameters.) In fact, Meta says: Number of parameters for each, Llama 3 8B and Llama 3 70B — Trained on two custom-built 24,000 GPU clusters – is one of the highest performing generative AI models available today.
That’s quite a claim. So how does Meta support that? Well, the company offers MMLU (attempts to measure knowledge), ARC (attempts to measure skill acquisition), and DROP (attempts to measure model acquisition over chunks of text). We point out the Llama 3 model’s scores on common AI benchmarks such as Testing Inference. As I’ve written before, the usefulness and validity of these benchmarks is debatable. But for better or worse, these are still one of the few standardized ways that AI players like Meta evaluate models.
Llama 3 8B outperforms other open models such as Mistral’s Mistral 7B and Google’s Gemma 7B in at least nine benchmarks: MMLU, ARC, DROP, and GPQA (a set of biology, physics, and chemistry). Both of these models contain 7 billion parameters. Related Questions), HumanEval (Code Generation Test), GSM-8K (Math Word Problems), MATH (Another Math Benchmark), AGIEval (Problem Solving Test Set), and BIG-Bench Hard (Common Sense Reasoning Assessment).
Now, Mistral 7B and Gemma 7B aren’t exactly at the forefront (Mistral 7B was released last September), and in some benchmarks cited by Meta, Llama 3 8B scores lower than either. It’s only a few percent higher. But Meta also claims that his Llama 3 70B, his Llama 3 model with more parameters, can compete with flagship generative AI models, including Gemini 1.5 Pro, the latest addition to Google’s Gemini series. I am.
Image credits: meta
Llama 3 70B outperforms Gemini 1.5 Pro in MMLU, HumanEval, and GSM-8K, and falls short of Anthropic’s most capable model, Claude 3 Opus, but Llama 3 70B is the second weakest model in the Claude 3 series It has a better score than. Claude 3 Sonnet, 5 benchmarks (MMLU, GPQA, HumanEval, GSM-8K, and MATH).
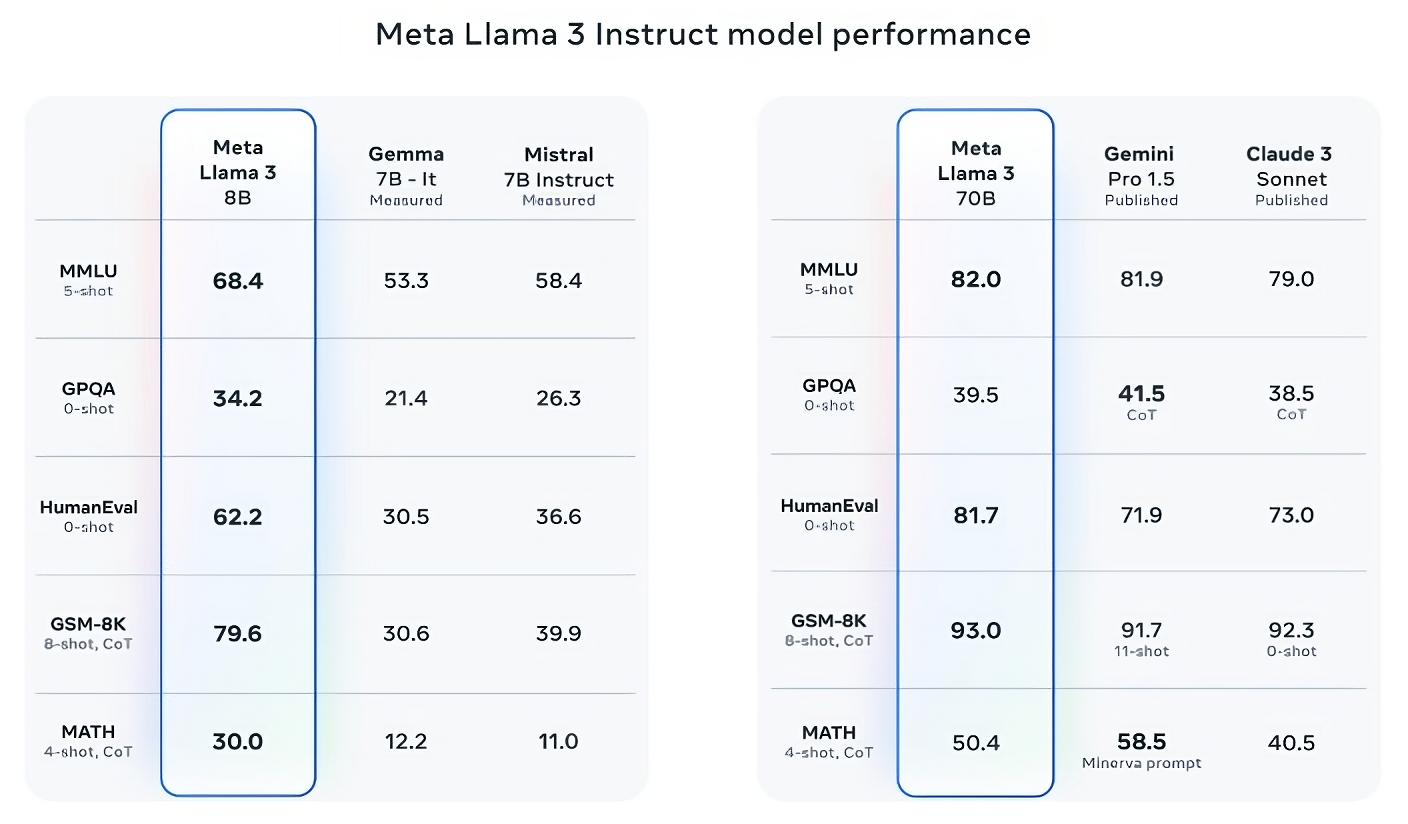
Image credits: meta
Additionally, Meta has also developed a unique set of tests that cover use cases ranging from coding and creative writing to inference and summarization. And surprisingly! — Llama 3 70B came out on top against Mistral’s Mistral Medium model, OpenAI’s GPT-3.5, and Claude Sonnet. Meta says it has prevented its modeling team from accessing the set to maintain objectivity, but clearly – given that Meta devised the test itself – the results should be taken with a grain of salt. There is.

Image credits: meta
More qualitatively, Mehta said users of the new Llama model will enjoy greater “usability”, a lower chance of refusing to answer questions, trivia questions, STEM fields such as history, engineering, science, and general It states that we should expect improved accuracy in coding questions. Recommendations. This is partly due to a much larger dataset. A collection of 15 trillion tokens, or a mind-boggling collection of approximately 750 million words, 7 times his Llama 2 training set. (In the AI field, “tokens” refer to bits of raw data, like the syllables “fan,” “tas,” and “tic” in the word “fantastic.”)
Where does this data come from? Good question. The meta is not stated explicitly, that it is taken from “publicly available sources”, that it contains more than 4 times as much code as the Llama 2 training dataset, and that 5% of that set contains non-English data for improvement. (approximately 30 languages). Performance in languages other than English. Meta also said that it used synthetic data, or AI-generated data, to create long documents for training the Llama 3 model. A somewhat controversial approach Because there are potential performance drawbacks.
“While the models we are releasing today are only fine-tuned for English output, the increased diversity of the data means that the models can better recognize nuances and patterns and perform more powerfully across a variety of tasks. ,” Meta wrote in a blog post shared with TechCrunch.
Many generative AI vendors view training data as a competitive advantage, so they hold the data and associated information close to their chests. However, the details of training data are also a potential source of IP-related litigation, which also prevents much from being revealed. recent reports In an effort to keep pace with its AI rivals, Meta revealed that at one point it was using copyrighted e-books for AI training, despite warnings from its own lawyers. Meta and OpenAI are the subject of an ongoing lawsuit brought by authors including comedian Sarah Silverman over allegations that the vendors misused copyrighted data for training.
But what about two other common problems with generative AI models: toxicity and bias?Including llama 2)? Is Llama 3 an improvement in those areas? Yes, the meta claims.
Meta has developed a new data filtering pipeline to improve the quality of model training data and updated its pair of generation AI safety suites, Llama Guard and CybersecEval, to prevent text misuse and unwanted generation. He says he tried to prevent it. Llama 3 model etc. The company is also releasing a new tool, Code Shield, designed to detect code in generated AI models that could introduce security vulnerabilities.
However, filtering is not foolproof. Tools like Llama Guard, CyberSecEval, and Code Shield have their limitations. (See also: Rama 2 trends Fabricate answers to questions and divulge personal health and financial information.) We will have to wait to see how the Llama 3 model performs in the real world, including testing by academics on alternative benchmarks.
According to Meta, the Llama 3 model is currently available for download and powers Meta’s Meta AI assistant on Facebook, Instagram, WhatsApp, Messenger, and the web, and will soon be available in a managed format across a wide range of cloud platforms, including AWS. It will be hosted. Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM, Snowflake. In the future, we will also offer versions of models optimized for hardware from AMD, AWS, Dell, Intel, Nvidia, and Qualcomm.
Llama 3 models are likely to become widely available. However, you’ll notice that I use “open” rather than “open source” to describe them. Despite that, meta claim, that the Llama family model is not as unconditional as people believe. Yes, it is available for both research and commercial use. However, meta is prohibited Developers will no longer be able to use Llama models to train other generative models, but app developers with more than 700 million monthly users will need to request a special license from Meta, which the company may or may not be granted at its discretion.
A more capable Llama model is coming.
Meta said it is currently training an Llama 3 model with a size of over 400 billion parameters. The model will have the ability to “speak in multiple languages”, ingest more data, and understand images and other modalities in addition to text, making the Llama 3 series possible. Along with open releases like Hugging Face. Idefics2.

Image credits: meta
“Our goals for the near future are to make Llama 3 multilingual and multimodal, have longer contexts, and continue to improve overall performance across cores. [large language model] They have abilities such as reasoning and coding,” Mehta wrote in a blog post. “There’s a lot more to come.”
surely.