
In a recent study, a team of researchers at Mistral AI announced Mixtral 8x7B, a language model based on a new Sparse Mixture of Experts (SMoE) model with open weights. Licensed under the Apache 2.0 license and as a sparse network with a mix of experts, Mixtral only serves as a decoder model.
The team shared that Mixtral’s feedforward block was selected from eight different parameter groups. Every layer and token has two parameter groups called experts, which are dynamically selected by the router network to process the tokens and additively combine their results. Because each token uses only a portion of the total parameters, this method can efficiently increase the parameter space of the model while maintaining control over cost and latency.
Mistral is pre-trained on multilingual data with a 32k token context size. It performs as well as or better than Llama 2 70B and GPT-3.5 on many benchmarks. One of its main advantages is the effective use of parameters, which reduces inference time for small batch sizes and allows higher throughput for large batch sizes.
Mixtral significantly outperformed Llama 2 70B in tests such as multilingual comprehension, coding, and mathematics. Experiments showed that Mixtral can effectively recover data from a 32,000-token context window, regardless of the length and position of the data within the sequence.
To ensure a fair and accurate evaluation, the team used the evaluation pipeline to rerun the benchmark and perform a detailed comparison between the Mixtral and Llama models. The assessment consists of a wide range of questions divided into categories such as Mathematics, Code, Reading Comprehension, Common Sense Thinking, World Knowledge, and General Aggregate Results.
Common sense reasoning tasks such as ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, and CommonsenseQA have been evaluated in a zero-shot environment. Among the world knowledge tasks assessed in the 5-shot format were TriviaQA and NaturalQuestions. BoolQ and QuAC were reading comprehension tasks assessed in a 0-shot environment. Mathematics tasks included GSM8K and MATH, and code-related tasks included Humaneval and MBPP. General integration results for AGI Eval, BBH, and MMLU are also included in the study.
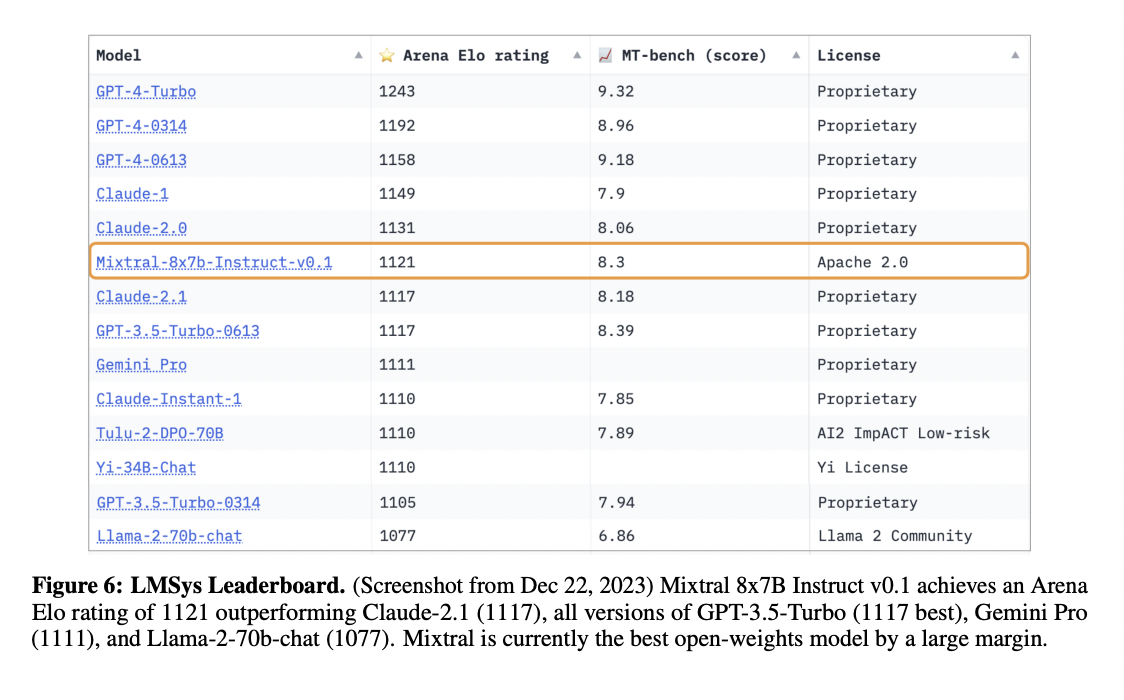
The study also introduced Mixtral 8x7B – Instruct, a conversational model optimized for instruction. Direct configuration optimization and supervised fine-tuning were used in this step. In human review benchmarks, Mixtral – Instruct performed better than GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B – Chat models. Benchmarks like BBQ and BOLD show less bias and a more balanced emotional profile.
To facilitate broad accessibility and a variety of applications, Mixtral 8x7B and Mixtral 8x7B – Instruct are both licensed under the Apache 2.0 License, which permits both commercial and academic use. The team modified his vLLM project by adding Megablocks CUDA kernels for effective inference.
In conclusion, this study highlights the outstanding performance of Mixtral 8x7B using thorough comparisons with Llama models on a wide range of benchmarks. Mixtral performs exceptionally well in a variety of activities, from math and coding problems to reading comprehension, reasoning, and general knowledge.
Please check paper and code. All credit for this study goes to the researchers of this project.Don’t forget to follow us twitter.participate 36,000+ ML SubReddits, 41,000+ Facebook communities, Discord channeland LinkedIn groupsHmm.
If you like what we do, you’ll love Newsletter..
Don’t forget to join us telegram channel


Tanya Malhotra is a final year student at University of Petroleum and Energy Research, Dehradun, pursuing a Bachelor’s degree in Computer Science Engineering with specialization in Artificial Intelligence and Machine Learning.
She is a data science enthusiast with good analytical and critical thinking, and a keen interest in learning new skills, leading groups, and managing work in an organized manner.
 “Real-time AI with Kafka and Streaming Data Analytics” (January 15, 2024, 10am PT)
“Real-time AI with Kafka and Streaming Data Analytics” (January 15, 2024, 10am PT)  Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish