
Language models (LMs) face significant privacy and copyright challenges as they are trained on vast amounts of text data. The inadvertent inclusion of private or copyrighted content in training datasets raises legal and ethical issues, including copyright lawsuits and compliance requirements with regulations such as GDPR. Data owners are increasingly seeking to remove data from trained models, highlighting the need for effective machine learning unlearning techniques. These developments have spurred research into how to transform existing trained models to behave as if they had never been exposed to certain data, while maintaining overall performance and efficiency.
Researchers have made various attempts to address the challenge of machine learning unlearning in language models. Exact unlearning techniques that aim to make the unlearned model identical to a model retrained without the forgotten data have been developed for simple models such as SVMs and naive Bayes classifiers. However, these approaches are computationally infeasible for modern large-scale language models.
Approximate unlearning techniques have emerged as more practical alternatives, including parameter optimization techniques such as Gradient Ascent, unlearning based on localization information that targets specific model units, and in-context unlearning that uses external knowledge to modify model outputs. Researchers have also explored applying unlearning to specific downstream tasks to eliminate harmful behaviors in language models.
Evaluation methods for unlearning machine learning language models have primarily focused on specific tasks such as question answering and sentence completion. Metrics such as familiarity scores and comparisons with retrained models have been used to evaluate the effectiveness of unlearning. However, existing evaluations often lack comprehensiveness and do not adequately address real-world deployment considerations such as scalability and sequential unlearning requirements.
Researchers from the University of Washington, Princeton University, University of Southern California, University of Chicago, and Google Research present MUSE (Machine Learning Unlearning Six-Way Evaluation), a comprehensive framework designed to evaluate the effectiveness of machine learning unlearning algorithms for language models. This systematic approach evaluates six key properties that address both data owner and model deployer requirements for practical unlearning. MUSE examines an unlearning algorithm’s ability to eliminate verbatim memorization, knowledge memorization, and privacy leakage, while also evaluating its ability to maintain usefulness, scale effectively, and maintain performance across multiple unlearning requests. By applying this framework to evaluate eight representative machine learning unlearning algorithms on datasets focused on unlearning Harry Potter books and news articles, MUSE provides a holistic view of the current state and limitations of unlearning techniques in real-world scenarios.

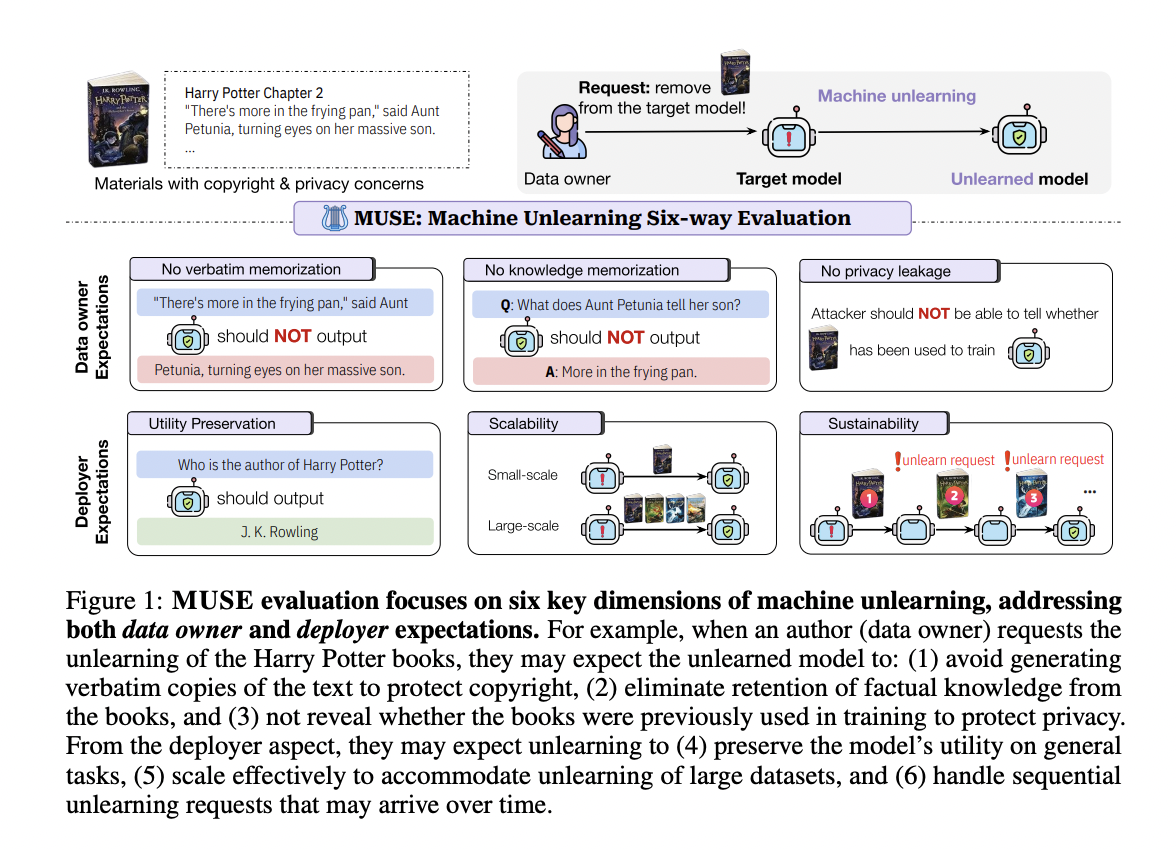
MUSE proposes a comprehensive set of evaluation metrics that meet the expectations of both data owners and model deployers for machine learning unlearning of language models. The framework consists of six main criteria:
Data Owner Expectations:
1. No verbatim memory: We present the model with the beginning of a sequence from the forgetting set and measure it by comparing the model’s continuation with the actual continuation using the ROUGE-L F1 score.
2. No memorized knowledge: We test the model’s ability to answer questions derived from the forgetting set and evaluate it by comparing the answers generated by the model with the actual answers using the ROUGE score.
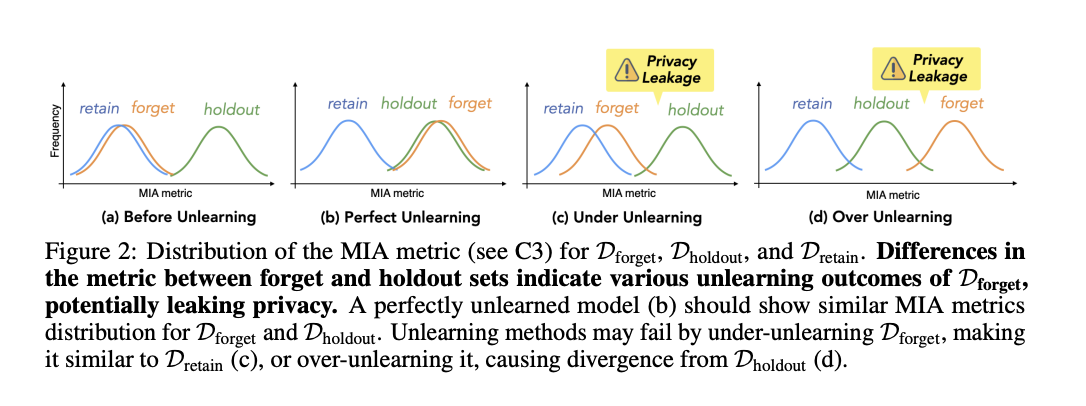
3. No Privacy Leakage: We evaluate using the Membership Inference Attack (MIA) technique to detect whether the model retains information that indicates that the forgotten set was part of the training data.
Model deployer expectations:
4. Utility preservation: It is measured by evaluating the model’s performance on the retention set using knowledge retention metrics.
5. Scalability: We evaluate it by examining the performance of the model on forgetting sets of different sizes.
6. Sustainability: Analyze the model performance by tracking it through successive unlearning requests.
MUSE evaluates these metrics on two representative datasets, NEWS (BBC news articles) and BOOKS (the Harry Potter series), providing a realistic testbed for evaluating unlearning algorithms in real-world scenarios.

Evaluation of eight unlearning techniques with the MUSE framework revealed significant challenges in machine unlearning of language models. Most techniques effectively removed verbatim and knowledge memorization, but suffered from privacy leakage issues and frequent under- or over-unlearning. All techniques significantly reduced the usefulness of the models, and some rendered them unusable. Scalability issues emerged as the size of the forgotten set increased, and successive unlearning requests created sustainability issues and gradually degraded performance. These findings highlight the significant trade-offs and limitations in current unlearning techniques and highlight the urgent need for more effective and balanced approaches that meet the expectations of both data owners and deployers.

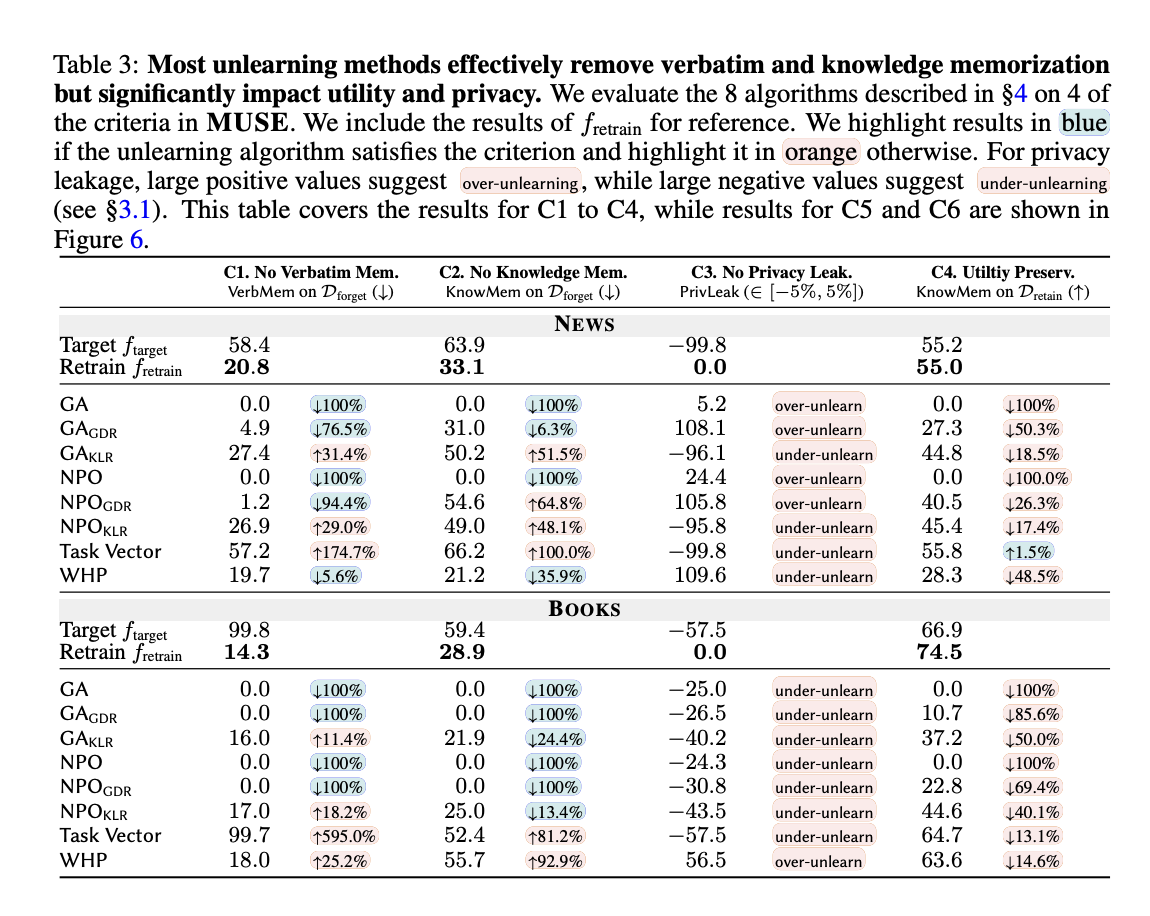
In this study, Museis a comprehensive machine learning unlearning evaluation benchmark that evaluates six key properties important to both data owners and model deployers. The evaluation reveals that current unlearning methods effectively prevent content memorization, but at a significant cost to the model utility of the retained data. These methods also often lead to significant privacy leakage and suffer from scalability and sustainability issues when dealing with large-scale content removal and successive unlearning requests. These findings highlight the limitations of existing approaches and the urgent need for the development of more robust and balanced machine learning unlearning techniques that can adequately address the complex requirements of real-world applications.
Please check paper and project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddit


Asjad is an Intern Consultant at Marktechpost. He is pursuing a B.Tech in Mechanical Engineering from Indian Institute of Technology Kharagpur. Asjad is an avid advocate of Machine Learning and Deep Learning and is constantly exploring the application of Machine Learning in Healthcare.