
Creating deep learning architectures is resource-intensive, requiring large design spaces, long prototyping periods, and expensive computations associated with training and evaluating large models. Architectural improvements are achieved through an opaque development process based on heuristics and personal experience rather than systematic steps. This is due to the explosion of possible design combinations and the lack of reliable prototyping pipelines, despite advances in automated neural architecture search methods. . The need for agile, principles-based design pipelines is further accentuated by the high costs and long iteration periods associated with training and testing new designs, exacerbating the problem.
Although there are a wealth of potential architectural designs, most models use a variant of the standard Transformer recipe that alternates between memory-based (self-attention layer) and memoryless (shallow FFN) mixers. The original Transformer design is the basis for this particular set of computational primitives that are known to improve quality. Empirical evidence suggests that these primitives excel at certain subtasks within sequence modeling, such as context and factual reproduction.
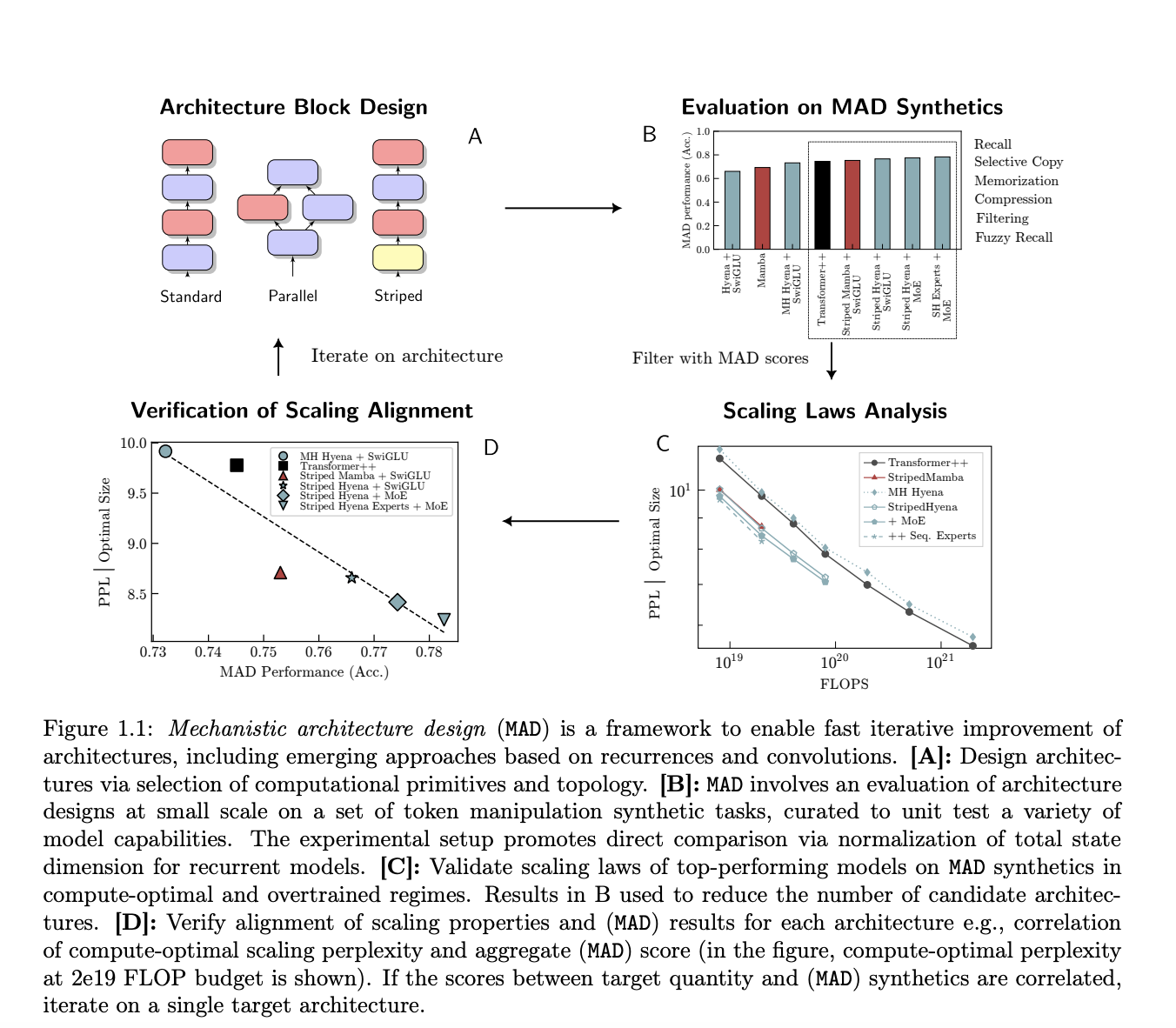
Researchers from Together AI, Stanford University, Hessian AI, RIKEN, Arc Institute, CZ Biohub, and Liquid AI are investigating architectural optimizations ranging from scaling rules to artificial activities that test specific model functionality. I am. They introduce Mechanical Architectural Design (MAD), an approach for rapid architectural prototyping and testing. MAD was chosen to serve as a discrete unit test for important characteristics of the architecture, consists of a set of synthetic activities such as compaction, storage, and reproduction, and requires only a few minutes of training time. The development of better ways to manipulate sequences, such as in-context learning and recall, has improved our understanding of the transformer-like sequence models that gave rise to the MAD problem.
The team used MAD to evaluate designs that used familiar and unfamiliar computational primitives, such as gate convolution, gate input variable linear recursion, and additional operators such as mixture of experts (MoE). To do. They use his MAD to filter and find potential candidates for the architecture. This led to the discovery and validation of various design optimization strategies, such as striping, which creates hybrid architectures by sequentially interleaving blocks composed of different computational primitives with a given connectivity topology.
Researchers trained 500 language models with different architectures and 70 billion to 7 billion parameters to perform the most extensive scaling law analysis on the architecture under development, improving MAD synthesis and real-world performance. We are investigating the relationship with scaling. Compute-optimized LSTM and transformer scaling rules are the basis of the protocol. Overall, the hybrid design outperforms the non-hybrid design in scaling and reducing pre-training losses over a range of FLOP computing budgets on the compute optimization frontier. Their work also shows that the new architecture is more resilient to extensive pre-training runs outside the optimal frontier.
State size, like the standard Transformer kv cache, is an important factor in MAD and its scaling analysis. This determines inference efficiency and memory cost, and probably directly affects recall ability. The research team proposes a state-optimal scaling method to estimate complexity scaling with state dimension for different model designs. They discovered a hybrid design that finds a good compromise between complexity, state dimensionality, and computing requirements.
By combining MAD with newly developed computational primitives, the state-of-the-art achieves a 20% reduction in complexity while maintaining the same computational budget as top-level Transformer, convolutional, and recurrent baselines (Transformer++, Hyena, Mamba). You can create hybrid architectures for
The findings have significant implications for machine learning and artificial intelligence. By demonstrating that a well-chosen set of her MAD simulation tasks can accurately predict the performance of scaling laws, the team opens the door to automated and faster architectural design. This is particularly relevant for models in the same architectural class, where the accuracy of MAD is closely related to the complexity of large-scale computational optimization.
Please check paper and github. All credit for this study goes to the researchers of this project.Don’t forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you’ll love Newsletter..
Don’t forget to join us 39,000+ ML subreddits
New research on mechanical architecture design and scaling laws.
– Perform the largest scaling law analysis (500+ models, up to 7B) beyond previous Transformer architectures
– For the first time, we demonstrate the performance of our architecture on a set of isolated tokens… pic.twitter.com/khJAXnvwWA
— Michael Poli (@MichaelPoli6) March 28, 2024


Dhanshree Shenwai is a computer science engineer with extensive experience in FinTech companies covering the fields of finance, cards and payments, and banking, with a keen interest in applications of AI. She is passionate about exploring new technologies and advancements in today’s evolving world to make life easier for everyone.
 Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more…
Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more… Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish