in July and September, 15 major AI companies have signed on to the White House’s voluntary initiative to manage the risks posed by AI. These promises include a promise to be more transparent, sharing information “with industry as a whole, government, civil society, and academia” and publicly reporting on the capabilities and limitations of AI systems. It was to do so. Sounds great in theory, but what does it mean in practice? What exactly is transparency when it comes to these AI companies’ large and powerful models?
Thanks to a report led by Stanford University Basic model research center (CRFM), these questions have been answered.The underlying models they are interested in are OpenAI’s GPT-4 and Google’s PaLM2, is trained on a huge amount of data and can be adapted to a variety of applications.of Underlying model transparency index We graded the 10 largest such models based on 100 different transparency metrics.
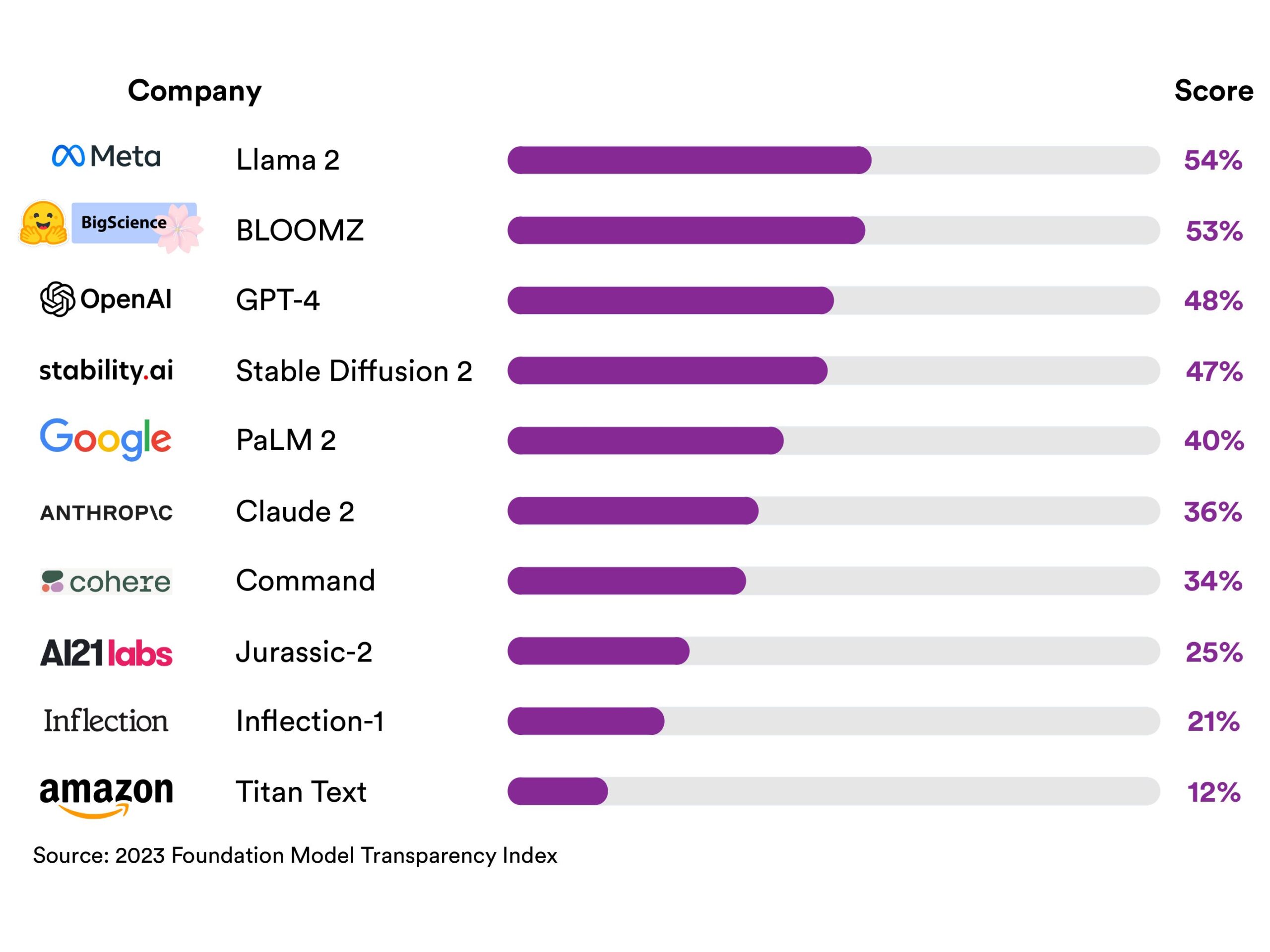
The highest total score goes to Meta’s Llama 2 with 54 out of 100.
They didn’t do very well.The highest total score will be the meta one llama 2, 54 points out of 100. In school, that is considered a failing grade. “None of the major underlying model developers have been able to provide adequate transparency,” the researchers wrote in their paper. blog post“Revealed a fundamental lack of transparency in the AI industry.”
Rishi BommasaniThe index is an effort to counter the alarming trends of the past few years, said the doctoral candidate at Stanford University’s CRFM and one of the project leaders. “As the impact grows, these models and companies become less transparent,” he says. Most notably, OpenAI writes that when it upgraded from GPT-3 to GPT-4, the company made the following decisions: withhold all information “Architecture (including model size), hardware, training computing, dataset construction, [and] training method. ”
The 100 indicators of transparency (fully listed in the blog post) include upstream factors related to training, information about model properties and capabilities, and downstream factors related to model distribution and use. “It is not enough for organizations to be transparent in announcing their models, as many governments are demanding,” he says. Kevin Kleiman, a research assistant at Stanford University’s CRFM and co-author of the report. “There also has to be transparency about the resources that go into that model, the evaluation of that model’s capabilities, and what happens after release.”
To evaluate the model based on 100 indicators, the researchers searched public data and gave the model a 1 or 0 for each indicator according to predetermined thresholds. We then followed up with 10 companies to see if they wanted to dispute their scores. “In some cases, there was information that we were missing,” Bommasani says.
spectrum We contacted representatives of various companies listed in this index. No one responded to requests for comment as of our deadline.
“Labor in AI is always a murky subject. And here it is very opaque, beyond the standards seen in other regions.”
—Rishi Bommasani, Stanford
The source of the training data for the underlying model is a hot topic. Severallawsuit It alleges that the AI company illegally included the author’s copyrighted material in its training dataset. And perhaps unsurprisingly, the Transparency Index showed that most companies are not being upfront about their data.model blooms from the developer hug face It received the highest score of 60% in this particular category. Other models did not score above 40%, and some models were zero.
The heatmap shows how the 10 models performed in different categories from data to impact. Stanford Basic Model Research Center
Companies have also remained largely silent on the labor issue, which is an important issue because the models require human workers to refine them. For example, OpenAI uses a process called reinforcement learning with human feedback to teach models like GPT-4 which responses are most appropriate and acceptable to humans. However, most development companies do not publicly disclose information about who these human workers are and the wages they are paid, leaving this workforce outsourced to low-wage domestic workers. There are concerns that this may be the case. places like kenya. “Labor in AI has always been a murky topic,” says Bommasani. “And it’s very opaque here, exceeding standards we’ve seen in other areas.”
Hugging Face is one of three index developers that Stanford University researchers have deemed “open,” meaning the model weights are widely downloadable. Three open models (Llama 2 by Meta, Bloomz by Hugging Face, stable diffusion Stability AI) currently leads in transparency, scoring above the best closed models.
Although these open models have earned transparency points, not everyone believes they are the most responsible actors in this field. There is currently a lot of debate about whether such a powerful model should be open sourced and made available to malicious parties. Just a few weeks ago, demonstrators stormed Meta’s San Francisco office, denouncing the “irreversible proliferation” of potentially dangerous technology.
Bommasani and Kleiman said the Stanford group is committed to maintaining the index and plans to update it at least once a year. With regulatory efforts underway in many countries, the team hopes policymakers around the world will look to this index when drafting legislation on AI. They say that if companies could increase transparency in the 100 different areas highlighted in the index, lawmakers would have better insight into which areas need intervention. “When there is pervasive uncertainty around labor and downstream impacts, there is a clear judgment that lawmakers should consider these things,” Bommasani said.
It’s important to remember that even if a model has a high transparency score in the current index, that doesn’t necessarily mean it’s a paragon of AI virtue. Companies would still score points for data and labor transparency if they disclosed that their models were trained on copyrighted material and improved by workers making less than minimum wage. .
As a first step, “we’re trying to bring the facts to the surface,” Bommasani said. “If we can have transparency, there is a lot more work to be done.”