
Machine learning has long recognized the effectiveness of tree ensembles such as random forests. These ensembles pool the predictive power of multiple decision trees and stand out for their remarkable accuracy across a variety of applications. This study by researchers at the University of Cambridge explains the mechanisms behind this success, offering a nuanced perspective beyond traditional explanations that focus on variance reduction.
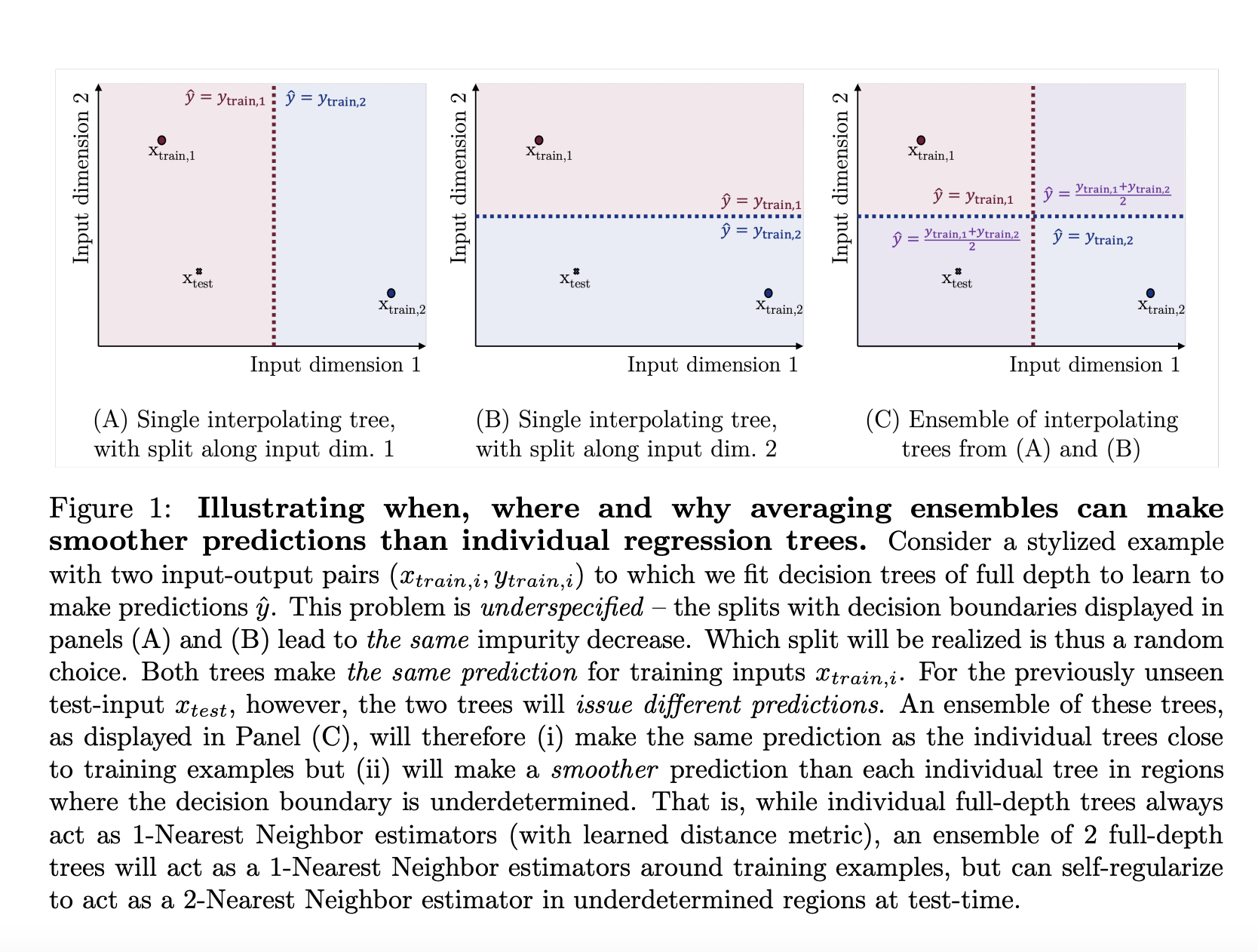
In this work, we liken the tree ensemble to an adaptive smoother. This is a conceptualization that reveals the ability to self-adjust and adjust predictions according to the complexity of the data. This adaptability is central to performance, allowing it to handle data complexity in ways that a single tree cannot. The predictive accuracy of the ensemble is enhanced by adjusting the smoothing based on the similarity between the test input and training data.

The core of the ensemble methodology is the integration of randomness in tree construction, which acts as a form of regularization. This randomness is not arbitrary, but a strategic element that contributes to the robustness of the ensemble. Ensembles can diversify predictions by introducing variability in feature and sample selection, reduce the risk of overfitting, and improve model generalizability.
The empirical analysis presented in the study highlights the practical implications of these theoretical insights. The researchers detail how tree ensembles significantly reduce the variance of predictions through adaptive smoothing techniques. This is demonstrated quantitatively through comparisons with individual decision trees, with ensembles showing significant improvements in predictive performance. In particular, ensembles have been shown to smooth predictions, effectively handle noise in the data, and improve reliability and accuracy.
In this work, we delve deeper into the performance and results and show convincing evidence of the ensemble’s superior performance through experimentation. For example, ensembles consistently showed lower error rates than individual trees when tested across a variety of datasets. This was quantitatively verified by the mean squared error (MSE) metric, which showed that the ensemble performed significantly better than a single tree. This study also highlights the ensemble’s ability to adjust the level of smoothing depending on the test environment, a flexibility that contributes to robustness.
What makes this study unique is its empirical findings and contribution to the conceptual understanding of tree assemblages. Researchers at the University of Cambridge are providing a new lens through which to view these powerful machine learning tools by configuring ensembles as adaptive smoothers. This perspective not only sheds light on the inner workings of ensembles, but also opens new avenues to enhance ensemble design and implementation.
In this study, we investigate the effectiveness of tree ensembles in machine learning based on both theory and empirical evidence. The adaptive smoothing perspective provides a compelling explanation for the success of ensembles, highlighting the ability of ensembles to self-adjust and adjust their predictions in ways that are not possible with a single tree. Incorporating randomness as a regularization technique further emphasizes the sophistication of the ensemble and contributes to improved prediction performance. Through detailed analysis, this study not only reaffirms the value of tree assemblages, but also deepens our understanding of their working mechanisms and paves the way for future advances in this field.
Please check paper. All credit for this research goes to the researchers of this project.Don’t forget to follow us twitter and google news.participate 38,000+ ML SubReddits, 41,000+ Facebook communities, Discord channeland LinkedIn groupsHmm.
If you like what we do, you’ll love Newsletter..
Don’t forget to join us telegram channel
You may also like Free AI courses….
Why do Random Forests perform so well off-the-shelf and appear to be essentially immune to overfitting??
I found the textbook answer “It’s just variance reduction
” to be a bit unspecific, so in a new preprint https://t.co/UXDO9ULnl6, @Jeffaresalan &I will investigate..
1/n pic.twitter.com/P3BPKNGrBp
— Alicia Curth (@AliciaCurth) February 26, 2024


Muhammad Athar Ganaie, Consulting Intern at MarktechPost, is an advocate of efficient deep learning with a focus on sparse training. A master’s degree in electrical engineering with a specialization in software engineering combines advanced technical knowledge with practical applications. His current work is a paper on “Improving the Efficiency of Deep Reinforcement Learning,” which demonstrates his commitment to enhancing the capabilities of AI. Athar’s research lies at the intersection of “sparse training of DNNs” and “deep reinforcement learning.”
 Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more…
Join the fastest growing AI research newsletter from researchers at Google + NVIDIA + Meta + Stanford + MIT + Microsoft and more… Arabic
Arabic Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish